llmstep: [L]LM proofstep suggestions in Lean
News
- [11.2023] Experimental Llemma suggestions that leverage file context
- [10.2023] New paper describing version 1.0.0 of
llmstep: [paper] - [10.2023] Support for Reprover
- [9.2023] Support for free GPU servers via Google Colab
llmstep is a Lean 4 tactic for suggesting proof steps using a language model:
Calling llmstep "prefix" gives suggestions that start with prefix:
example (f : ℕ → ℕ) : Monotone f → ∀ n, f n ≤ f (n + 1) := by
intro h n
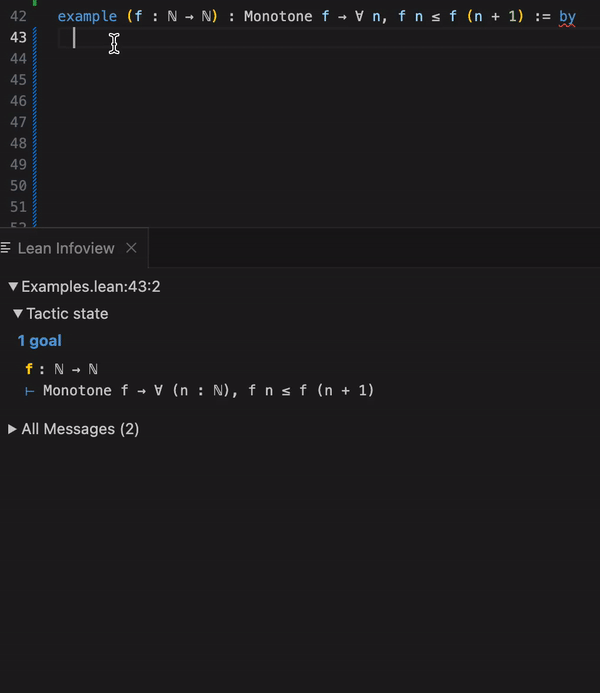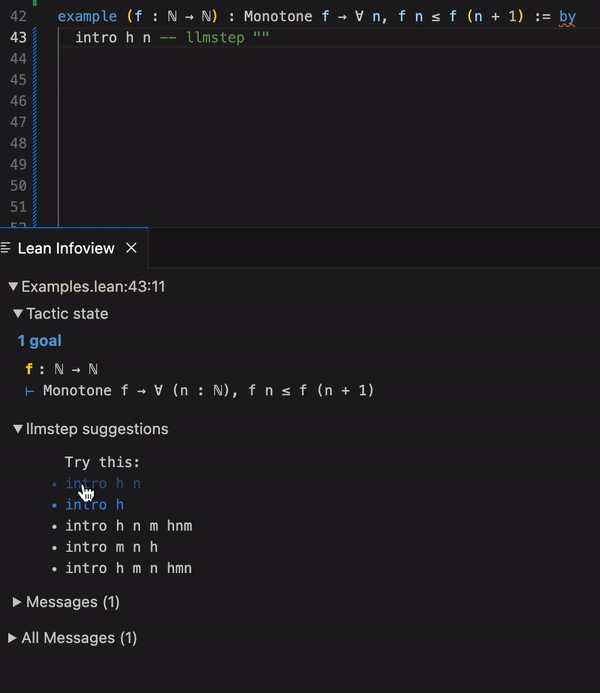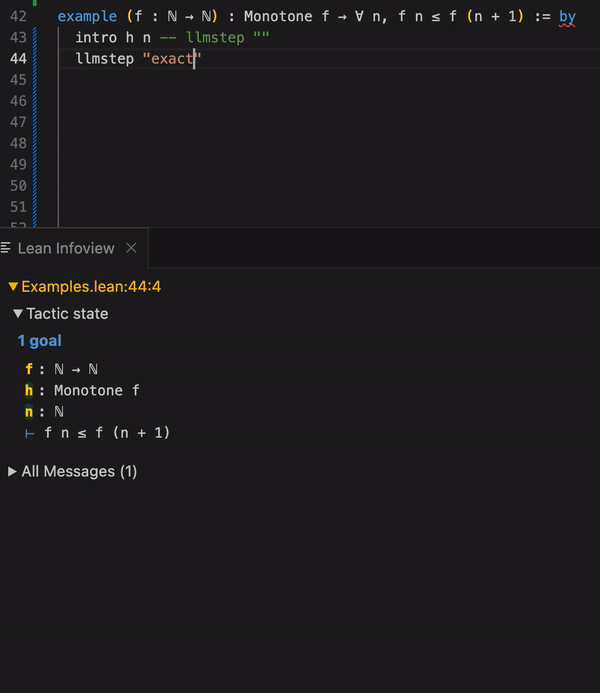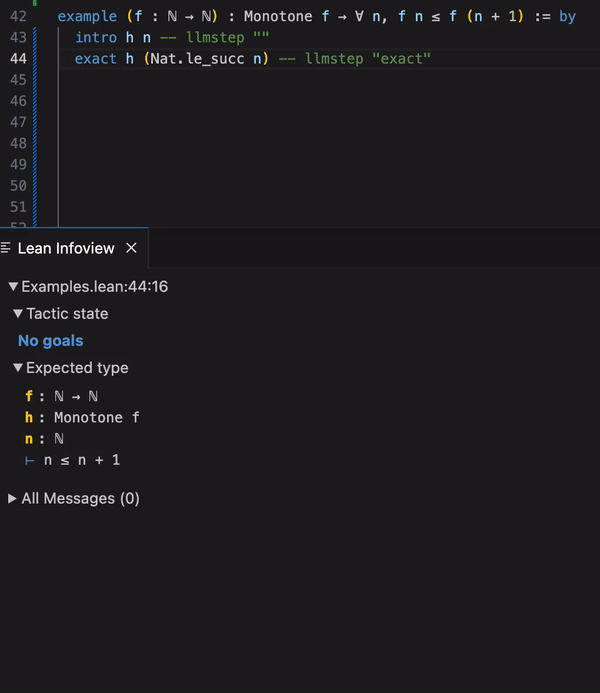
llmstep "exact"
==> Lean Infoview
Try This:
* exact h (Nat.le_succ _)
* exact h (Nat.le_succ n)
* exact h (Nat.le_add_right _ _)
Clicking a suggestion places it in the proof:
example (f : ℕ → ℕ) : Monotone f → ∀ n, f n ≤ f (n + 1) := by
intro h n
exact h (Nat.le_succ _)
llmstep checks the language model suggestions in Lean, and highlights those that close the proof.
Quick start
First, install Lean 4 in VS Code and the python requirements (pip install -r requirements.txt).
Then start a server:
python python/server.py
Open LLMstep/Examples.lean in VS Code and try out llmstep.
Use llmstep in a project
- Add
llmstepinlakefile.lean:
require llmstep from git
"https://github.com/wellecks/llmstep"
Then run lake update.
- Import
llmstepin a Lean file:
import LLMstep
- Start a server based on your runtime environment. For instance:
python python/server.py
Please see the recommended servers below.
Servers
The llmstep tactic communicates with a server that you can run in your own environment (e.g., CPU, GPU, Google Colab).
The table below shows the recommended language model and server scripts.
To start a server, use python {script}, e.g. python python/server_vllm.py:
| Environment | Script | Default Model | Context | Speed | miniF2F-test |
|---|---|---|---|---|---|
| CPU | python/server_encdec.py | LeanDojo ByT5 300m | State | 3.16s | 22.1% |
| Colab GPU | See Colab setup | llmstep Pythia 2.8b | State | 1.68s | 27.9% |
| CUDA GPU | python/server_vllm.py | llmstep Pythia 2.8b | State | 0.25s | 27.9% |
| CUDA GPU* | python/server_llemma.py | Llemma 7b | State, current file 🔥 | N/A | N/A |
Please refer to our paper for further information on the benchmarks.
llmstep aims to be a model-agnostic tool. We welcome contributions of new models.
* File context support (e.g. with Llemma) is currently experimental.
Implementation
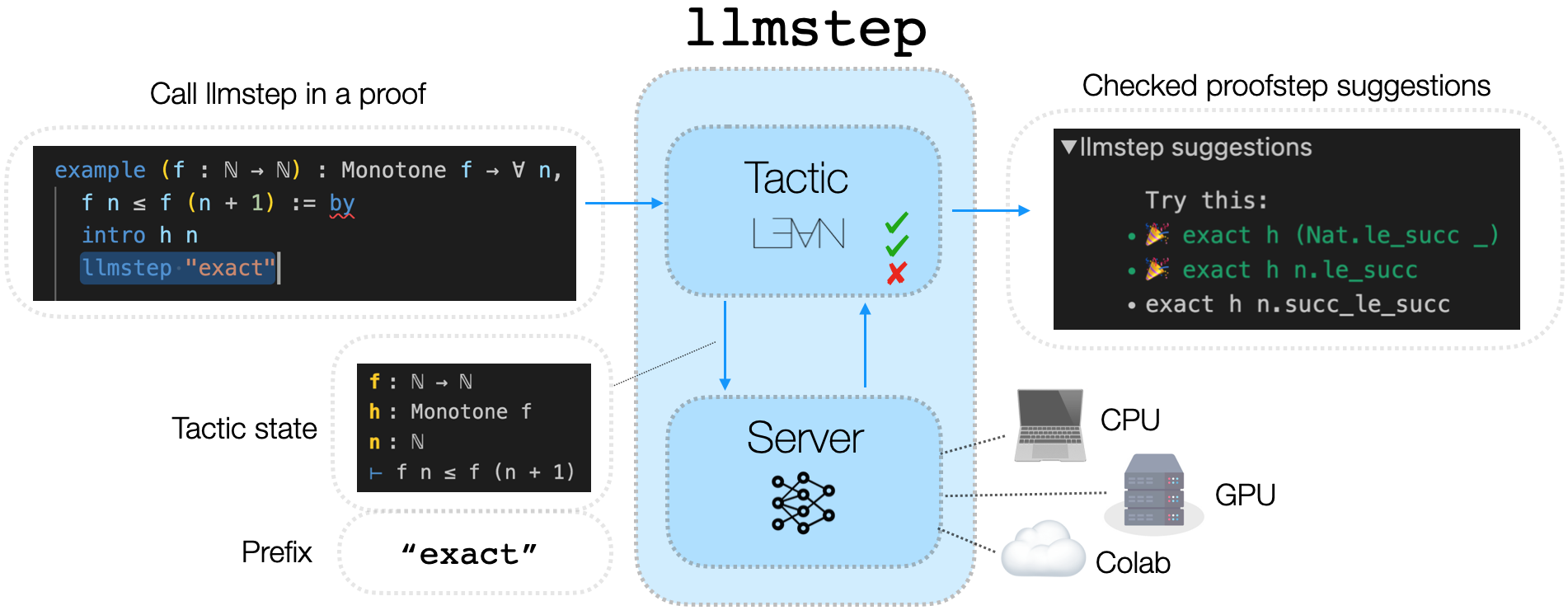
llmstep has three parts:
The Lean tactic sends a request to the server.
The server calls the language model and returns the generated suggestions.
The suggestions are displayed by the tactic in VS Code.
Google Colab
To use Google Colab's free GPU to run a server, follow these instructions:
-
Open and run this notebook to start a server:

-
In your local environment, set the environment variable
LLMSTEP_HOSTequal to the url printed out in this notebook (for example,https://04fa-34-125-110-83.ngrok.io/). -
In your local environment, set the environment variable
LLMSTEP_SERVER=COLAB. -
Use
llmstep.
VS Code steps (2) and (3)
To set environment variables in VS Code, go to:
-
Settings (
Command+,on Mac) -
Extensions -> Lean 4
-
Add the environment variables to
Server Env. For example:
-
Then restart the Lean Server (
Command+t, then type> Lean 4: Restart Server):
Language model
By default, llmstep uses a Pythia 2.8b language model fine-tuned on LeanDojo Benchmark 4:
The python/train directory shows how the model was fine-tuned.
Reprover
You can use the non-retrieval version of Reprover, which we refer to as LeanDojo ByT5 300m:
python python/server_encdec.py
By default, this runs the leandojo-lean4-tacgen-byt5-small model.
This model is particularly useful on CPU due to its small parameter count.
Using a different model
Swap in other decoder-only language models with the --hf-model argument:
python server.py --hf-model some/other-model-7B
Use --hf-model with python/server_encdec.py for encoder-decoder models.
Use --hf-model with python/server_llemma.py for prompted base models (e.g. CodeLlama).
Fine-tuning a model
The scripts in python/train show how to finetune a model.
Additional Notes
Acknowledgements
- The
llmsteptactic is inspired bygpt-f. - Fine-tuning data for the Pythia-2.8b model is from LeanDojo.
- The fine-tuning code is based on the script from Stanford Alpaca.
- The tactic implementation adopts ideas and code from Mathlib4's
PolyrithandStd.Tactic.TryThis. - Thank you to Mario Carneiro and Scott Morrison for reviewing the tactic implementation.
History
llmstep was initially created for an IJCAI-2023 tutorial on neural theorem proving.
It aims to be a model-agnostic platform for integrating language models and Lean.
Citation
Please cite:
@article{welleck2023llmstep,
title={LLMSTEP: LLM proofstep suggestions in Lean},
author={Sean Welleck and Rahul Saha},
journal={arXiv preprint arXiv:2310.18457},
year={2023}
}